Dansactoren in kaart gebracht
Het afgelopen jaar brachten we dansactoren in kaart, met een focus op klassieke dans en ballet. Wat was het doel van dit project? Hoe gingen we te werk? En welke visualisaties konden we aan de hand van de dataset maken? In dit verslag lees je het antwoord op die vragen.
Wat is de taak en het doel van het project?
CEMPER wil muziek- en podiumkunstenerfgoed in kaart brengen. We begonnen met actoren uit de klassieke dans en het klassieke ballet. Het in kaart brengen van die actoren geeft ons een basis om hun archieven en collecties op te sporen en kan inzicht verschaffen op de netwerken van deze actoren.
Bij het in kaart brengen van deze dansactoren hadden we twee bijkomende doelen voor ogen. Als eerste wilden we de dataset importeren in de vernieuwde databank van Archiefpunt (Archiefbank Vlaanderen). Vervolgens wilden we onderzoeken welke visualisaties we konden maken met deze dataset aan de hand van enkele tools die we hier hebben toegelicht.
Werkproces
Opbouw van de dataset dansactoren
Vooreerst hebben we nagedacht over welke informatie we het best konden verzamelen en hoe we die het best konden registreren. Door af te bakenen en te kiezen voor een focus op klassieke dans en ballet hebben we diverse actoren in kaart kunnen brengen. Die keuze was nodig vanwege het ruime veld aan dansstijlen en soorten dans.
Omdat we deze dataset wilden inbrengen in Archiefbank – CEMPER werkt structureel samen met deze databank van Archiefpunt voor de registratie van collecties en archieven – hebben we hun datastructuur overgenomen. Door de structuur over te nemen was deze uitwisselbaar met zowel Archiefbank als met de tools die we later gebruikten voor de visualisaties.
Vervolgens hadden we bronnen nodig voor het maken van de veldtekening. Hier konden we rekenen op enkele publicaties zoals: Ongehinderd door woorden: Een geschiedenis van dans als kunstvorm in België, 1890 – 1940 van Staf Vos (2009), Van Operaballet naar ballet van Vlaanderen van Rina Barbier (1973), ‘Les Trois Coups’ Belge, de geschiedenis van de theaterdans in België geschreven door Jeanne Brabants (1994) en Dans en ballet van A tot Z van Rina Barbier en Bert Westra (1997).
Het doornemen van deze fysieke bronnen was tijdsintensief en verschilde ook van publicatie tot publicatie. De ene had een persoonsindex waardoor actoren die in de publicatie voorkomen waren gebundeld, de ander had dan weer geen inhoudstafel wat het zoeken en registreren bemoeilijkte. In dat geval namen we de publicatie volledig door voor het extraheren van actoren met de bijbehorende context. Denk hierbij aan gegevens als activiteiten, beroepen (functies), een korte persoonsgeschiedenis, plaatsen waar de actor actief was, een naamsverandering van een dansgezelschap of de opvolging van een directeur bij een theaterorganisatie.
Contextinformatie werd waar nodig aangevuld met internetbronnen. We hebben databanken zoals Kunstenpunt, Anet, ODIS, de oude databank van Muziekcentrum en TheaterEncyclopedie gebruikt. Ook artikels werden geraadpleegd in tijdschriften zoals Etcetera (tijdschrift voor podiumkunsten) en Documenta: tijdschrift voor theater of andere internetbronnen zoals Oxford Reference en Dictionary, websites van de kunstenaars, choreografen, dansers, dansscholen of ‑groepen. Verder vonden we het een plezier als er sporadisch een video van de danser verscheen in de zoekresultaten of dat we een leuk wist-je-datje ontdekten.
Voor andere actoren was er maar weinig informatie te vinden. Hier konden we enkel een basisregistratie van de naam, het type actor, (wanneer bekend of gevonden) een geboorte- of sterfdatum en de bron invullen in onze informatievelden. De dataset met historische dansactoren hebben we later aangevuld met extra lijsten die CEMPER al eerder verzamelde. Hierdoor werd onze dataset aangevuld met hedendaagse en nog actieve actoren uit dans en ballet. Helaas kunnen we geen exhaustieve veldtekening maken van alle actoren uit klassieke dans en ballet.
Na het verzamelen van deze informatie konden we de dataset opschonen. Naast het verbeteren van spel- en schrijffouten hebben we informatie uit één veld opgesplitst naar verschillende velden, onderwerpstermen geüniformiseerd en andere handelingen uitgevoerd die de data bruikbaar maken. Een voorbeeld hiervan is het uniformiseren van persoonsnamen die in verschillende bronnen anders geschreven zijn of een pseudoniem waaronder de actor is gekend verbinden met een officiële naam.
Vanaf het schonen ontstonden er twee lijsten voor onze twee doelen: één voor Archiefbank, de tweede om analyses en visualisaties mee te maken. Door de originele dataset op te splitsen konden we andere klemtonen leggen op de data.
De lijst voor Archiefbank hebben we opgebouwd naar een voorbepaalde datastructuur ter voorbereiding van een import van onze dataset in de nieuwe databank van Archiefbank.
Bij de tweede lijst was het belangrijk om de informatie uit de verschillende velden waaruit de dataset is opgebouwd — bij wijze van spreken — verder uit elkaar te trekken. Daardoor ontstond er een één-op-éénrelatie met de actor en de informatie uit het veld. De volgende stap was het maken van de analyses. Hierover hebben we enkele vragen geformuleerd als basis voor het maken van deze analyses en later voor de visualisaties.
Tot slot was het aangeraden om tussen de stappen door back-ups te maken van de datasets. Zo zorgden we ervoor dat de informatie niet verloren zou gaan bij automatiseringen, het opsplitsen van kolommen of andere handelingen. Hierdoor konden we waar nodig op stappen terugkomen. Een foutje is al snel gemaakt, waardoor het een geruststelling is dat je de oorspronkelijke data terug kan ophalen.
Visualisaties
Visualisaties helpen om data op een andere manier te presenteren waardoor nieuwe inzichten en conclusies gemaakt kunnen worden. Door het gebruik van visualisaties kan je ook verschillende verhalen die in je data zitten op een toegankelijke manier vertellen. Anders gezegd: je vertaalt je data naar een visueel verhaal.
Zoals hierboven al aangehaald hebben we nagedacht over enkele vragen waarop de visualisatie een antwoord of een inzicht zou kunnen geven. Uiteraard is dat sterk afhankelijk van de gegevens die je verzamelde en de manier waarop je die verzamelde. Deze aanpak bood een houvast in het analyseren van de data van onze dansactoren en later het maken van de visualisaties.
Enkele programma’s en tools die we hebben gebruikt voor onze visualisaties waren Excel, Airtable en Flourish. Bij de laatste twee hebben we de niet-betalende versies gebruikt. Hoewel de drie programma’s onderling sterk verschillen, bieden ze een laagdrempelige manier aan om visualisaties te maken. Ze kunnen beschouwd worden als praktijkvoorbeelden.
Airtable
Airtable wordt vaak gebruikt voor marketing en product operations, maar het programma is flexibel voor een breder gebruik ervan, zoals onze dataset van dansactoren. Een andere reden waarom we Airtable gebruikten was vanwege de lage leercurve, het intuïtief gebruik en de mogelijkheid mensen uit te nodigen binnen een bepaald project.
Airtable is een relationele databank, dat wil zeggen dat je verschillende tabellen aan elkaar kan linken door in de ene tabel een relatie of link te leggen naar een record in een andere tabel. Voor onze dataset dansactoren hebben we eerst stilgestaan bij de relationele opbouw. Hier kan het handig zijn om de opbouw ervan uit te tekenen zodat je een beeld krijgt waar relaties worden gelegd en hoe de structuur samenhangt.
Na de opbouw van de datastructuur kan je verder automatiseren en verschillende interfaces opbouwen. De interfaces bieden de kans om de data op een dynamische, interactieve en meer aantrekkelijke manier te presenteren.
Een nadeel aan Airtable is dat je (binnen een niet-betalend account) slechts een beperkt aantal records kan ingeven. Voor onze dansactoren hadden we al snel die limiet overschreden. Andere limieten waren het beperkt aantal templates en soorten interfaces die we konden gebruiken voor de opbouw van onze visualisaties, omwille dezelfde reden: omdat we de niet-betalende versie gebruikten. De visualisaties en interfaces die je maakt, kunnen niet op een andere website geëmbed worden om te presenteren of ermee in interactie te gaan.
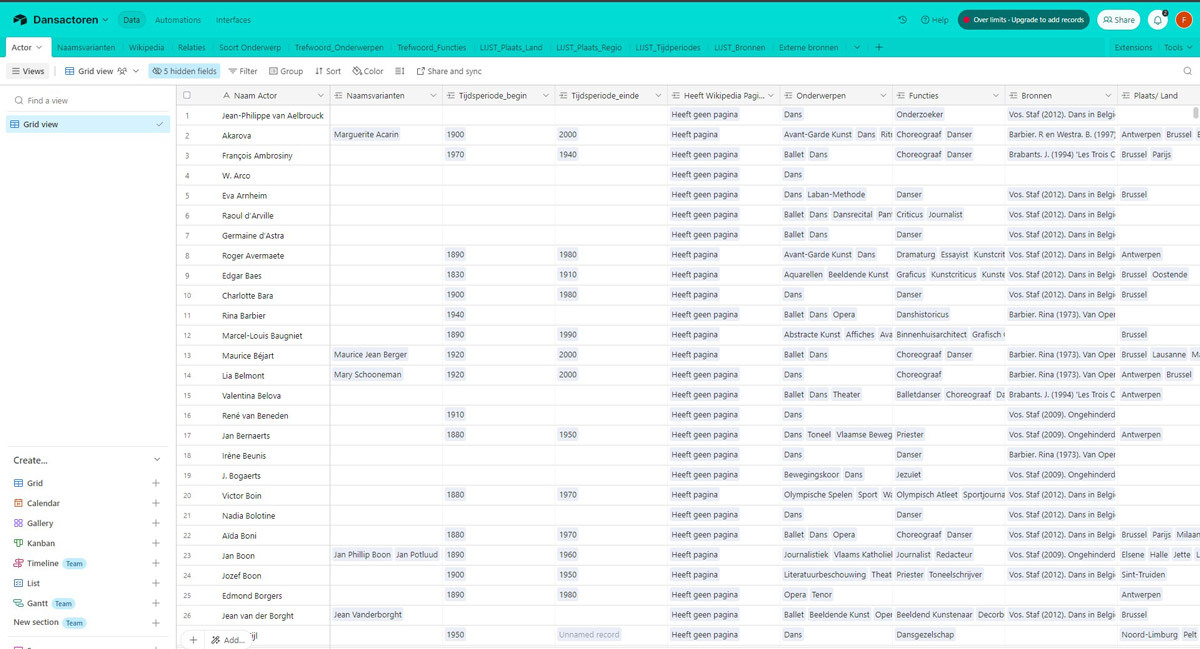
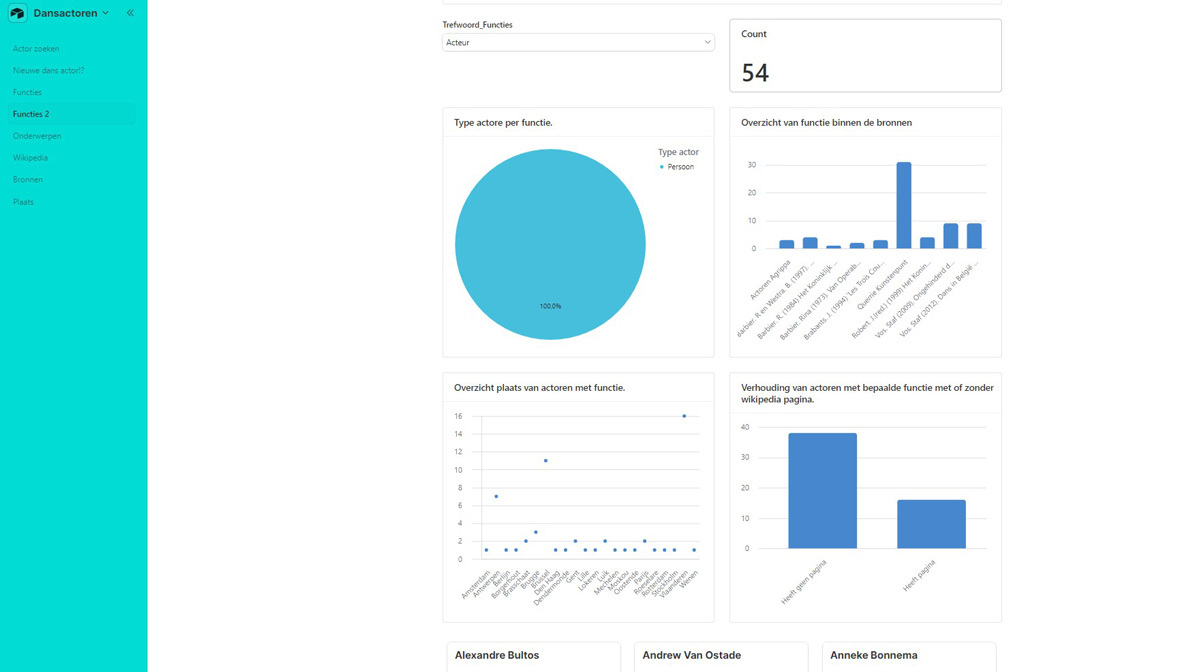
Excel
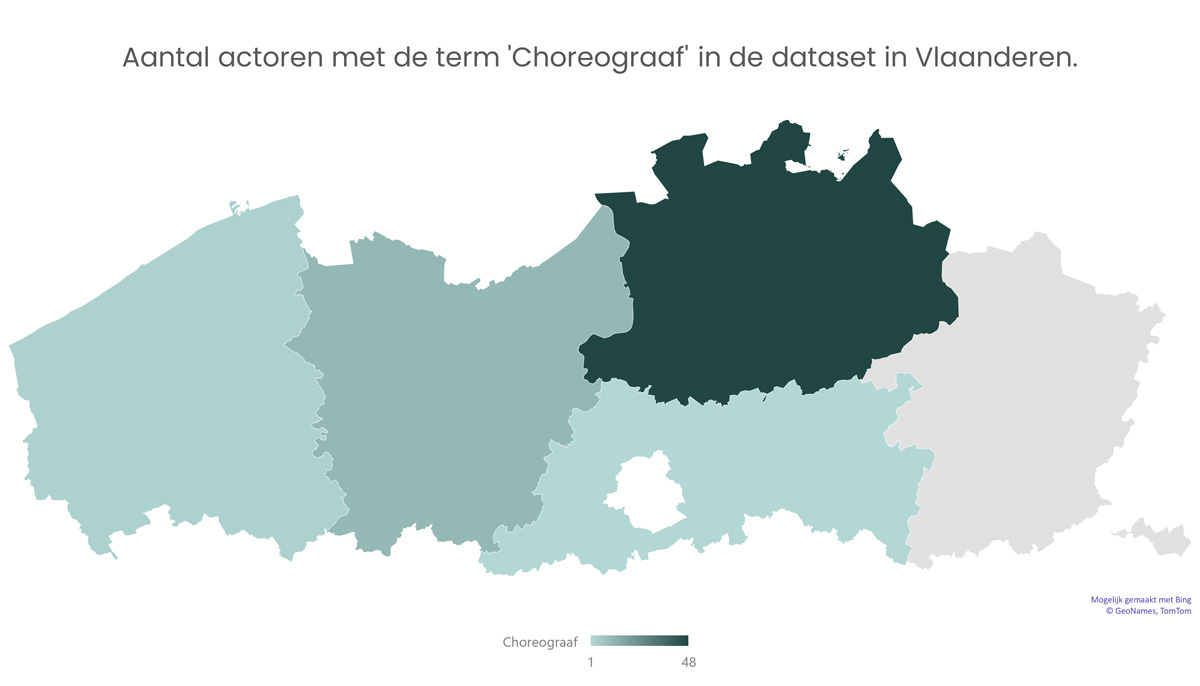
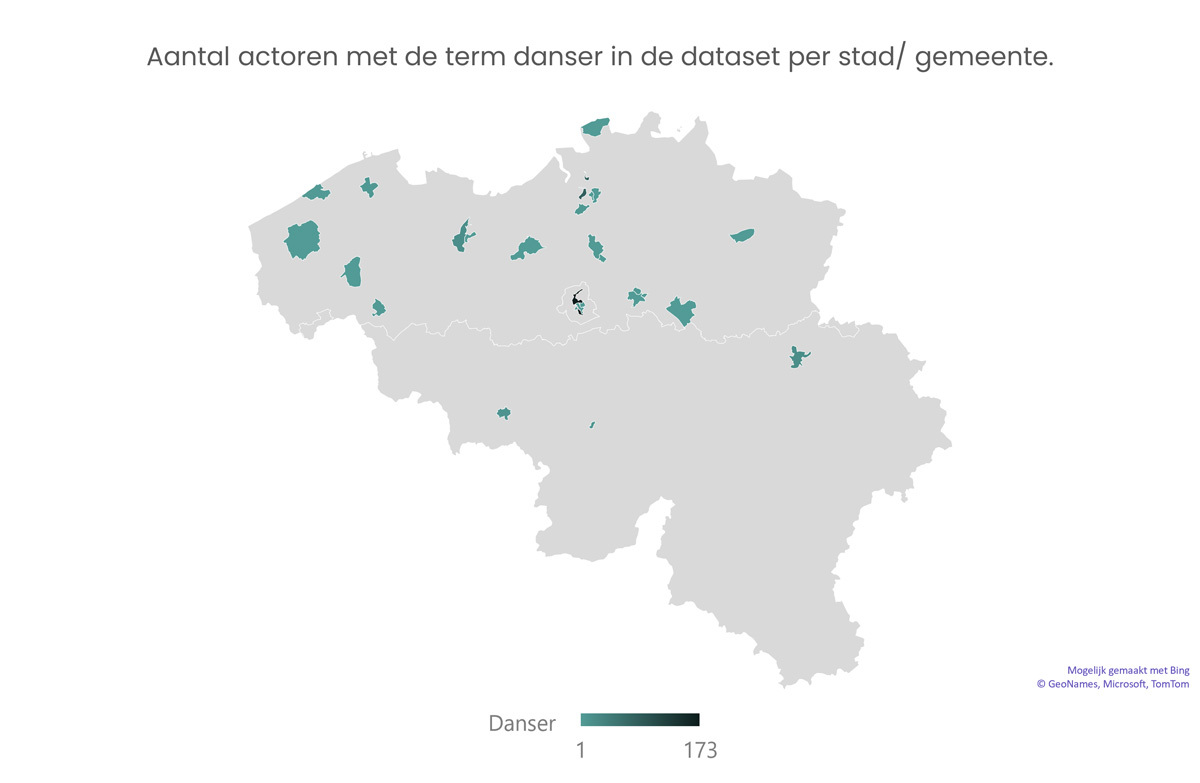
Ook Excel hebben we gebruikt om een aantal analyses en visualisaties te maken. Excel laat toe standaardgrafieken te maken, maar ook enkele zaken waarvan we verrast waren. Excel bleek soms een aanvulling te zijn waar andere tools ons beperkten vanwege een paywall. Een voorbeeld hiervan zijn de kaarten die we konden maken voor de dansers in Vlaanderen en Brussel.
Voor onze dansactoren bood het de kans om op een onderzoekende manier verhoudingen in de dataset te visualiseren. Eén voorbeeld is de verhouding tussen het gebruik van de verschillende bronnen of een analyse over het gebruik van bepaalde trefwoorden in de tijd.
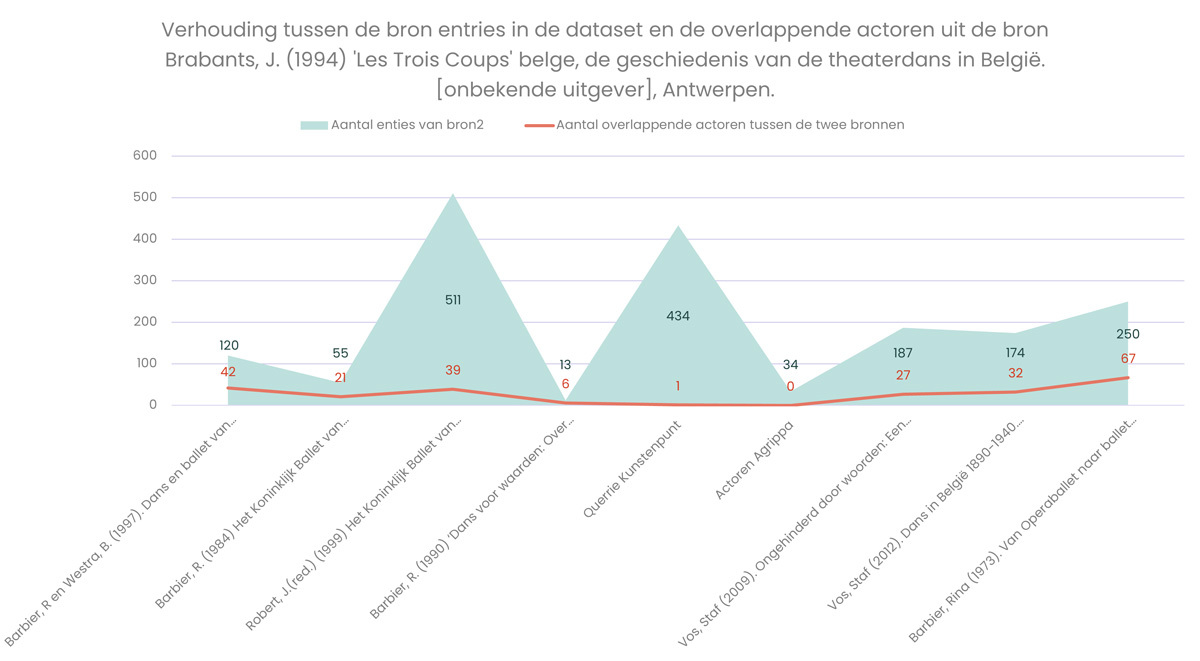
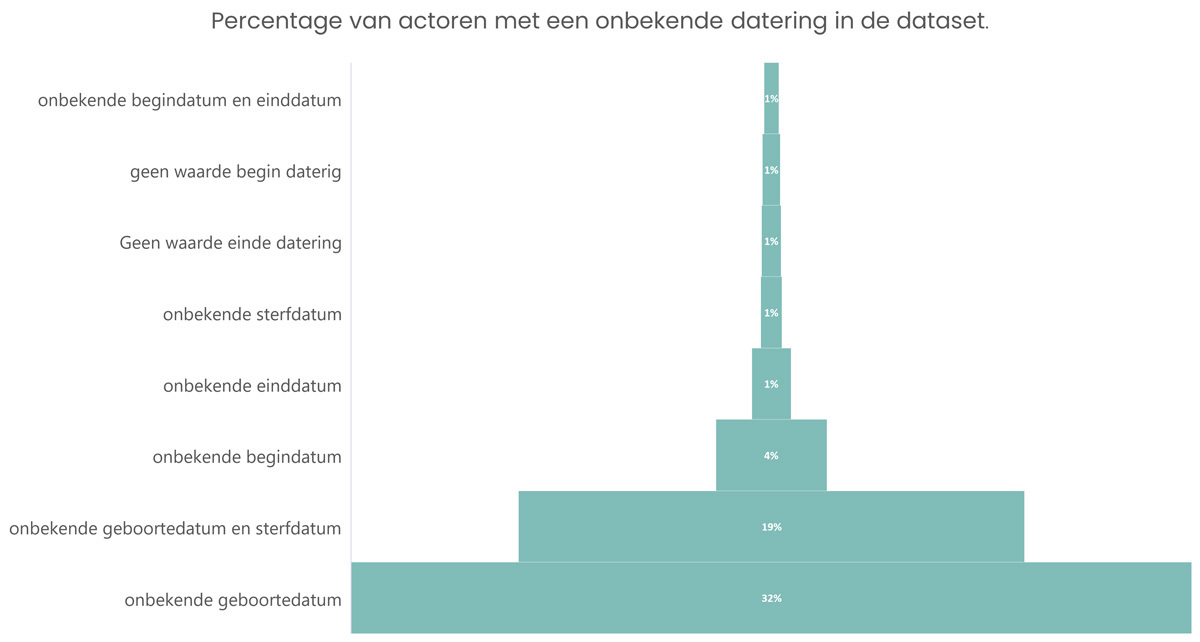
Flourish
Flourish is een online programma waarmee je data op een dynamische manier kan visualiseren en verhalend uitwerken. Flourish heeft een hele reeks van diverse templates waarvan sommige functionaliteiten betalend zijn.
Het is een intuïtief en laagdrempelig programma waarbij je al een voorbeeld krijgt van hoe de achterliggende data zijn gestructureerd voor de opbouw van de visualisatie. Een voordeel van het gebruik van Flourish is dat visualisaties geëmbed kunnen worden in een website.
Hieronder een voorbeeld waarin geïllustreerd wordt uit welke bronnen de meeste actoren komen.
Een nadeel van Flourish is dat we de data sterk moesten vereenvoudigen, want voor bepaalde visualisaties waren die te complex en divers. Maar dit ondervonden we eveneens bij het gebruik van andere tools.
Hieronder een voorbeeld van complexe data in een netwerk, waarin plaatsen gelinkt worden aan actoren.
Resultaat en bevindingen
De drie voorbeelden van programma’s en tools voor visualisaties hebben elk hun sterktes en zwaktes. Het zijn slechts drie voorbeelden van de vele tools en programma’s die er te vinden zijn. Ze bieden elk een andere manier van hoe je data kan presenteren en visualiseren.
Door deze veldtekening van dansactoren te gebruiken voor het maken van visualisaties kregen we inzicht in het dans- en balletveld in het verleden, maar ook van de lacunes in onze dataset. Met andere woorden: het is een oefening die ons enkele nieuwe inzichten gaf. Het bood ons eveneens de kans om actoren uit het verleden te doorzoeken en op een systematische manier te beschrijven en analyseren.
Ook interessant

MetX: Interculturele muzikale erfgoedzorg in beweging

‘25 jaar Brussels Volkstejoêter’ in AMVB

Besparingen treffen danserfgoed
